#encoding:gbk
import pandas as pd
import numpy as np
import time
import datetime
import calendar
from scipy import stats
import tensorflow as tf
import warnings
warnings.filterwarnings("ignore")
def get_holdings(accountid,datatype):
holdinglist={}
resultlist=get_trade_detail_data(accountid,datatype,"POSITION")
for obj in resultlist:
holdinglist[obj.m_strInstrumentID+"."+obj.m_strExchangeID]=obj.m_nVolume
return holdinglist
def get_portfolio(accountid,datatype):
result=0
resultlist=get_trade_detail_data(accountid,datatype,"ACCOUNT")
for obj in resultlist:
result=obj.m_dAvailable
return result
def timetag_to_date(timetag, format):
timetag = timetag/1000
#time_local = time.localtime(timetag)
return time.strftime(format,format)
def init(ContextInfo):
ContextInfo.index = '000016.SH'
#ContextInfo.stocks = ContextInfo.get_sector('000300.SH')
#ContextInfo.set_universe(ContextInfo.stocks)
ContextInfo.stype = 'index'
ContextInfo.accountID='110000035020'
ContextInfo.isFirst = True
ContextInfo.factors = ['Beta','btop',
'etop','cetop','etp5','earning_yield',
'agro']
#,'rstr','lncap',
#'净利率', '净资产收益率', '毛利率','资产收益率',
#'资产负债率','市盈率','流通市值']
'''
ContextInfo.factors = ['Beta.beta','btop.btop',
'EARNINGS_YIELD.etop','EARNINGS_YIELD.cetop','EARNINGS_YIELD.etp5','EARNINGS_YIELD.earning_yield',
'GROWTH.agro',
'MOMENTUM.rstr','NLSIZE.lncap',
'净利率.考虑披露期延迟净利率', '净资产收益率.考虑披露期延迟净资产收益率', '毛利率.考虑披露期延迟毛利率','资产收益率.考虑披露期延迟资产收益率',
'资产负债率.考虑披露期延迟资产负债率','市盈率.考虑披露期延迟市盈率','流通市值.流通市值']
'''
ContextInfo.financials = ['PERSHAREINDEX.du_return_on_equity', 'PERSHAREINDEX.sales_gross_profit', 'PERSHAREINDEX.inc_revenue_rate',
'ERSHAREINDEX.du_profit_rate', 'PERSHAREINDEX.inc_net_profit_rate','PERSHAREINDEX.adjusted_net_profit_rate',
'PERSHAREINDEX.inc_total_revenue_annual', 'PERSHAREINDEX.inc_net_profit_to_shareholders_annual', 'PERSHAREINDEX.adjusted_profit_to_profit_annual',
'PERSHAREINDEX.equity_roe', 'PERSHAREINDEX.net_roe', 'PERSHAREINDEX.total_roe',
'PERSHAREINDEX.gross_profit', 'PERSHAREINDEX.net_profit', 'PERSHAREINDEX.actual_tax_rate',
'PERSHAREINDEX.gear_ratio', 'PERSHAREINDEX.inventory_turnover']
ContextInfo.shift = 12 # 回溯时间步
ContextInfo.training_iters = 1000 # 单周期训练次数
ContextInfo.stop = 20 # 停下来查看loss的时间步
ContextInfo.lr = 0.05 # 学习率
ContextInfo.n_hidden_units = 100 # neurons in hidden layer
ContextInfo.lstm_size = ContextInfo.n_hidden_units # 单层 lstm 的 hidden_units 数量
ContextInfo.n_layers = 2 # lstm 层数
def handlebar(ContextInfo):
index = ContextInfo.index
shift = ContextInfo.shift
barpos = ContextInfo.barpos
realtime = ContextInfo.get_bar_timetag(barpos)
ContextInfo.current_dt = timetag_to_datetime(realtime,'%Y%m%d')
today = ContextInfo.current_dt
bkstart = ContextInfo.start
bkend = ContextInfo.end
#bkstartday = substr(bkstart)
#bkday = substr(bkend)
#preDate1 = datetime.datetime.strptime(today, "%Y%m%d") + datetime.timedelta(days = -shift)
#preDate = preDate1.strftime('%Y%m%d')
#preDate2 = datetime.datetime.strptime(today, "%Y%m%d") + datetime.timedelta(days = -1)
#ContextInfo.previous_date = preDate2.strftime('%Y%m%d')
#print(preDate, type(preDate))
index = ContextInfo.index
#获取股票列表
if ContextInfo.stype == 'index':
ContextInfo.stocks = ContextInfo.get_sector(index)#, realtime)
elif ContextInfo.stype == 'industry':
ContextInfo.stocks = ContextInfo.get_industry(index)
elif ContextInfo.stype == 'sector':
ContextInfo.stocks = ContextInfo.get_stock_list_in_sector(index, realtime)
else:
ContextInfo.stocks = index
ContextInfo.set_universe(ContextInfo.stocks)
stockList = ContextInfo.stocks
factorslist = ContextInfo.factors
set_slip_fee(ContextInfo)
print('时间戳获取中……')
tradingday = ContextInfo.get_trading_dates('000001.SH', '', today, shift+1, '1d')
shift_index_pred = list(tradingday).index(today) # 获取today对应的绝对日期排序数
pred_days = tradingday[shift_index_pred - shift+1 : shift_index_pred+1] # 获取回溯需要的日期array
start_date_pred = pred_days[0]
end_date_pred = pred_days[-1]
ContextInfo.previous_date =pred_days[-1]
print('pred:', start_date_pred, end_date_pred)
# 训练时间list
shift_index_train = list(tradingday).index(today) -1 # 获取yesterday对应的绝对日期排序数
train_days = tradingday[shift_index_train - shift+1 : shift_index_train+1 ]
start_date_train = train_days[0]
end_date_train = train_days[-1]
#ContextInfo.previous_date =train_days[-1]
print('train:',start_date_train, end_date_train, ContextInfo.previous_date)
'''
#剔除ST股
st_data=get_extras('is_st',stockList, count = 1,end_date = date)
stockList = [stock for stock in stockList if not st_data[stock][0]]
#剔除停牌、新股及退市股票
stockList=delect_stop(stockList,date,date)
# stockList = stockList[:9]
'''
print('训练数据获取中……')
x_tech_train = get_train_x(ContextInfo, stockList,factorslist,start_date_train, end_date_train)
#print(x_tech_train)
#x_fund_train = get_fund(ContextInfo, stockList, start_date_train, end_date_train)
#print(x_fund_train)
#x_train = pd.concat([x_tech_train, np.transpose(x_fund_train, (1,0,2))], axis =2)
#x_train = pd.concat([x_tech_train, x_fund_train], axis=1)
#print(x_train)
x_train = x_tech_train
y_train = get_train_y(ContextInfo, stockList, start_date_train, end_date_train)
print('预测预备数据获取中……')
x_tech_pred = get_train_x(ContextInfo, stockList,factorslist,start_date_pred, end_date_pred)
#x_tech_pred = x_tech_train
# x_fund_pred = get_fund(stockList, pred_days,industry_old_code,industry_new_code)
x_pred = x_tech_pred
print('单周期数据准备完成!!')
# 参数
training_iters = ContextInfo.training_iters # 单周期训练次数
stop = ContextInfo.stop # 停下来查看loss的时间步
lr = ContextInfo.lr # 学习率
n_hidden_units = ContextInfo.n_hidden_units # neurons in hidden layer
lstm_size = n_hidden_units # 单层 lstm 的 hidden_units 数量
n_layers = ContextInfo.n_layers # lstm层数
print('获取预测标的中……')
#print(x_train)
x_sub_train = x_train.get_values().astype(np.float32)#array(x_train.astype(np.float32))
y_sub_train = y_train.get_values().astype(np.float32)#array(y_train.astype(np.float32))
x_test = x_pred.get_values().astype(np.float32) #array(x_pred.astype(np.float32))
# 参数
n_inputs = (x_sub_train.shape[2]) # 输入参数维度
n_steps = (x_sub_train.shape[1]) # time steps
n_classes = y_sub_train.shape[2] # 分类元素
n_layers = ContextInfo.n_layers # lstm层数
lr = ContextInfo.lr # 学习率
training_iters = ContextInfo.training_iters # 训练次数
stop = ContextInfo.stop # 停止步数
print('预测中……')
pred = lstmtrain(x_sub_train, y_sub_train, x_pred, n_hidden_units,n_inputs, n_classes,n_steps,n_layers,lr, training_iters, stop)
#print('pred:', pred)
print('获取买入卖出池子中……')
buy,sell,df = get_buy_sell(pred, y_train, stockList)
buy_position = get_buy_position(df,buy)
print('预测结果:',df)
print('买入配资', buy_position)
print('买入池子:',buy)
print('卖出池子:',sell)
ContextInfo.buy = list(buy_position.index)
ContextInfo.sell = sell
ContextInfo.buy_position = buy_position
sell = list(sell)
# 止盈止损池子
today = ContextInfo.current_dt
yesterday = ContextInfo.previous_date
yesterday = str(yesterday)
holdinglist = get_holdings(ContextInfo.accountID,'STOCK')
#print('holdinglist', holdinglist)
for stock in holdinglist:
floating_return = get_floating_return(ContextInfo, stock,yesterday,today)
if floating_return < -0.03 or floating_return > 0.1:
list(sell).append(stock)
ContextInfo.sell = list(sell)
market_open(ContextInfo)
# 【根据涨幅t1/t0倍数加权建仓】
def market_open(ContextInfo):
print('【开盘】(market_open):'+str(ContextInfo.current_dt))
df_buy = ContextInfo.buy_position
buy = ContextInfo.buy
sell = ContextInfo.sell
ContextInfo.holdings = get_holdings(ContextInfo.accountID,"STOCK")
print(ContextInfo.holdings)
# 获取每个标的的配资权重
weight_for_stocks = {}
for stock in df_buy.index:
weight_for_stocks[stock] = list(df_buy.ix[stock])[-1]
cash = get_portfolio(ContextInfo.accountID,'STOCK')
# 买入股票
for stock in ContextInfo.buy:
if stock not in ContextInfo.holdings:
order_value(stock, weight_for_stocks[stock]*cash, ContextInfo, ContextInfo.accountID)
print('买入',stock)
for stock in ContextInfo.sell:
if stock in ContextInfo.holdings:
order_target_percent(stock, 0, 'COMPETE', ContextInfo, ContextInfo.accountID)
print('卖出',stock)
# 设置滑点手续费
def set_slip_fee(ContextInfo):
# 将滑点设置为0
ContextInfo.set_slippage(1, 0.0)
# 根据不同的时间段设置手续费
dt = ContextInfo.current_dt
if dt > '20130101': #datetime.datetime(2013,1, 1):
commissionList = [0.0003,0.0013,0.0003, 0.0003, 0, 5]
elif dt > '20110101': #datetime.datetime(2011,1, 1):
commissionList = [0.001,0.002,0.0003, 0.0003, 0, 5]
elif dt > '20090101':#datetime.datetime(2009,1, 1):
commissionList = [0.002,0.003,0.0003, 0.0003, 0, 5]
else:
commissionList = [0.003,0.004,0.0003, 0.0003, 0, 5]
ContextInfo.set_commission(0, commissionList)
def get_data_from_date(ContextInfo, start_date,end_date,stocks):
'''
获取时间轴数据
'''
trade_date = ContextInfo.get_trading_dates(stocks, start_date,end_date, 1, '1d')
print(trade_date[0])
df = get_factors_one_stock(stocks,trade_date[0])
for date in trade_date[1:]:
df1 = get_factors_one_stock(stocks,date)
df = pd.concat([df,df1])
return df
def get_fund(ContextInfo, stockList, start_date_pre, end_date_pre):
fieldList = ['PERSHAREINDEX.du_return_on_equity', 'PERSHAREINDEX.sales_gross_profit', 'PERSHAREINDEX.inc_revenue_rate',
'ERSHAREINDEX.du_profit_rate', 'PERSHAREINDEX.inc_net_profit_rate','PERSHAREINDEX.adjusted_net_profit_rate',
'PERSHAREINDEX.inc_total_revenue_annual', 'PERSHAREINDEX.inc_net_profit_to_shareholders_annual', 'PERSHAREINDEX.adjusted_profit_to_profit_annual',
'PERSHAREINDEX.equity_roe', 'PERSHAREINDEX.net_roe', 'PERSHAREINDEX.total_roe',
'PERSHAREINDEX.gross_profit', 'PERSHAREINDEX.net_profit', 'PERSHAREINDEX.actual_tax_rate',
'PERSHAREINDEX.gear_ratio', 'PERSHAREINDEX.inventory_turnover']
x_fund = ContextInfo.get_financial_data(fieldList, stockList,start_date_pre, end_date_pre, report_type = 'announce_time')
return x_fund
# 训练数据获取
# 单周期训练数据【x】
def get_train_x(ContextInfo, stockList, factorslist, start_date_pre, end_date_pre):
x_train = pd.DataFrame(columns=ContextInfo.factors)
timeArray = time.strptime(start_date_pre, "%Y%m%d")
start = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
timeArrayend = time.strptime(end_date_pre, "%Y%m%d")
end = time.strftime("%Y-%m-%d %H:%M:%S", timeArrayend)
data = ext_data_range(factorslist[0],'000001.SH' ,start,end, ContextInfo)
dfdate = pd.DataFrame.from_dict(data, orient='index', columns=['Beta'])
dfdate.index.name = 'dates'
del dfdate['Beta']
#dfdate.index.map(substr)
dfdate2 = dfdate.rename(index = substr)
#print('*******:',dfdate2)
# 训练数据【x】
input_data1 = {}
for stock in stockList:
ddd = dfdate2
for factor in factorslist:
factor_data= ext_data_range(factor,stock ,start,end,ContextInfo)
dffactor = pd.DataFrame.from_dict(factor_data, orient='index', columns=[factor])
#dffactor.index.name = 'dates'
#dffactor.index.map(substr)
dffactor2 = dffactor.rename(index = substr)
#print(dffactor2)
ddd = ddd.join(dffactor2, on='dates')
#print(ddd)
dffund = ContextInfo.get_financial_data(ContextInfo.financials, [stock],start_date_pre, end_date_pre, report_type = 'announce_time')
dfalldata = pd.concat([ddd, dffund], axis=1)
#dfalldata = ddd
#print(dfalldata)
# 有些因子没有的,用别的近似代替
#dfalldata.fillna(0, inplace = True)
#input_data1[stock] = dfalldata
# 去inf
a = np.array(dfalldata)
where_are_inf = np.isinf(a)
a[where_are_inf] = 'nan'
dfdata =pd.DataFrame(a, index=dfalldata.index, columns = dfalldata.columns)
#print(dfalldata.columns)
dfdata.fillna(0, inplace = True)
data_pro = winsorize_and_standarlize(dfdata)
#print('##############', data_pro)
input_data1[stock] = data_pro
#print('##############', type(input_data1), input_data1)
#print('****************', input_data1)
x_train = pd.Panel(input_data1)
#print(type(x_train), x_train)
return x_train
# 单周期训练数据【y】
def get_train_y(ContextInfo, stockList, start_date_last, end_date_last):
# 训练数据【y】
input_data = {}
for i in stockList:
data = ContextInfo.get_market_data(['close'], stock_code = [i],
start_time = start_date_last, end_time = end_date_last, skip_paused = True,
period = ContextInfo.period, dividend_type = 'none', count = ContextInfo.shift)
#print(data[data.columns[0]])
data = data[data.columns[0]]
input_data[i] = pd.DataFrame(data)
y_train = pd.Panel(input_data) # 训练因子数据
return y_train
# 【取每一时间步的输出为拿来训练的预测值】多层LSTM, 输出结果就是prediction
def multi_layer_lstm_for_each_step(X, n_lstm_layer, n_hidden_units, n_inputs, n_classes,n_steps,n_layers):
# n_lstm_layer: lstm的层数
# lstm_size 为 单层lstm的hidden_units的个数
# 权重
W = {
# (n_inputs, hidden_units)
'in': tf.Variable(tf.truncated_normal([n_inputs, n_hidden_units]), name ='in'),
# (hidden_units, n_classes)
'out': tf.Variable(tf.truncated_normal([n_hidden_units, n_classes]), name ='out')
}
b = {
# (n_hidden_units)
'in': tf.Variable(tf.constant(0.1, shape = [n_hidden_units]), name ='in'),
# (n_classes)
'out': tf.Variable(tf.constant(0.1, shape = [n_classes]), name ='out'),
}
# 放入 lstm 前的 hidden_layer
_x = tf.transpose(X, [1,0,2]) # permute n_steps and batch_size
# new shape (n_steps, batch_size, n_inputs)
# reshape to prepare input to hidden activation
_x = tf.reshape(_x, [-1, n_inputs])
# new shape: (n_steps * batch_size, n_input )
# ReLu activation
_x = tf.nn.relu(tf.matmul(_x, W['in']) + b['in'])
# Split data because rnn_cell needs a list of inputs for the RNN inner loop
_x = tf.split(_x, n_steps, 0)
# new shape: n_steps * (batch_size, n_hidden)
_x = tf.transpose(_x, [1,0,2])
# new shape: (batch_size, n_steps, hidden_units)
# 定义多层lstm
layers = [tf.contrib.rnn.BasicLSTMCell(num_units=n_hidden_units,
activation=tf.nn.relu)
for layer in range(n_layers)]
multi_layer_cell = tf.contrib.rnn.MultiRNNCell(layers)
# 运算RNN
output,final_states = tf.nn.dynamic_rnn(multi_layer_cell,_x,dtype=tf.float32)
# output 为每一个时间步隐藏层的输出值,shape:(batch_size, n_step, hidden_units)
# 放入 lstm 前的 hidden_layer
_output = tf.transpose(output, [1,0,2]) # permute n_steps and batch_size
# new shape (n_steps, batch_size, hidden_units)
_output = tf.reshape(_output, [-1, n_hidden_units])
# # new shape: (n_steps * batch_size, n_input )
# ReLu activation
_output = tf.nn.relu(tf.matmul(_output, W['out']) + b['out'])
# Split data because rnn_cell needs a list of inputs for the RNN inner loop
_output = tf.split(_output, n_steps, 0)
# new shape: n_steps * (batch_size, n_hidden)
_output = tf.transpose(_output, [1,0,2])
# new shape: (batch_size, n_steps, hidden_units)
pred = _output
return pred
# 单周期多层lstm预测
def lstmtrain(x_sub_train, y_sub_train, x_pred, n_hidden_units,n_inputs, n_classes,n_steps,n_layers,lr, training_iters, stop):
# 单周期多层LSTM(加上回溯前面周期)训练 +预测
warnings.filterwarnings("ignore")
tf.reset_default_graph()
n_inputs = (x_sub_train.shape[2]) # 输入参数维度
n_steps = (x_sub_train.shape[1]) # time steps
n_classes = y_sub_train.shape[2] # 分类元素
# 单层lstm
# prediction = single_layer_lstm_for_last_step(x, lstm_size)
# prediction = single_layer_lstm_for_each_step(x, lstm_size)
# # 多层lstm
#n_layers = 2
#prediction = multi_layer_lstm_for_last_step(x, n_layers, n_hidden_units)
prediction = multi_layer_lstm_for_each_step(x_sub_train, n_layers, n_hidden_units, n_inputs, n_classes,n_steps,n_layers)
#损失函数,均方差
# y_cost = tf.transpose(y,[1,0,2]) # 转换格式 (时间步,标的数量,分类结果)
# y_cost_for_train = y_cost[-1] # 提取样本内最后一个时间步(周期)的分类结果, shape=(标的数量,分类结果【一维数据,1 or 0】)
# MSE损失函数
loss = tf.reduce_mean(tf.square(y_sub_train - prediction))
# loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=prediction, labels=y))
#梯度下降: AdamOptimizer 收敛速度快,但是过拟合严重
train_step = tf.train.AdamOptimizer(learning_rate=lr).minimize(loss) #learning_rate可以调整
# # 预测
# correct_pred = tf.equal(tf.argmax(prediction,1), tf.argmax(y,1))
# accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer()) # 初始化
train_loss_list = []
for epoach in range(training_iters):
sess.run(train_step)
if epoach % stop == 0:
# 训练误差
loss_train = sess.run(loss)
train_loss_list.append(loss_train)
# 预测
pred = sess.run(prediction)
print ('Iter' + str(epoach) + ' Training Loss:' + str(loss_train) )
return pred
# 获取买入卖出池子
def get_buy_sell(pred,y_train,stockList):
# 整合结果
# 上一个交易日的收盘价
df_y_t0 = dict(np.transpose((y_train),(1,0,2)))[list(dict(np.transpose((y_train),(1,0,2))).keys())[-1]]
# 本交易日预测价格
p = np.transpose(pred, (1,0,2))
df_pred = pd.DataFrame(p[-1])
df_pred.index = df_y_t0.index
# 整合
df = pd.concat([df_y_t0, df_pred], axis =1)
df.columns = ['t0','pre_t1']
# 获取预测标的池子
diff1 = (df['pre_t1']-df['t0'])
# 表格整理
df1 = df.copy()
df1['buy_decision'] = 0
for i in range(len(df)):
if list(diff1)[i] > 0:
df1.iloc[i,2] = True
else :
df1.iloc[i,2] = False
# 买入池子
buy = []
for i in range(len(diff1)):
if list(diff1)[i] > 0 :
buy.append(diff1.index[i])
# 卖出池子
sell = set(stockList) - set(buy)
return buy,sell,df1
# 获取标的日间浮动收益率
def get_floating_return(ContextInfo, stock,yesterday,today):
#print( [stock], str(yesterday), str(today), ContextInfo.period)
a = ContextInfo.get_market_data(['close'], [stock], yesterday,today, True,ContextInfo.period, 'none', 2)
past_p = list(a['close'])[0]
current_p = list(a['close'])[-1]
floating_return = current_p/past_p -1
return floating_return
# 【资金加权】
def get_buy_position(df,buy):
# 涨跌幅获取
df['increase_pct'] = df['pre_t1']/df['t0']
# 提取预测涨的股票
df_buy = df.ix[buy]
# 降序
df_buy = df_buy.sort_values(by = ['increase_pct'], ascending = False)
# 配资比率
df_buy['buy%'] = df_buy['increase_pct']/sum(df['increase_pct'])
return df_buy
def substr(dtstr):
data = dtstr[0:4]+dtstr[5:7]+dtstr[8:10]
return data
def winsorize_and_standarlize(data,qrange=[0.05,0.95],axis=0):
'''
input:
data:Dataframe or series,输入数据
qrange:list,list[0]下分位数,list[1],上分位数,极值用分位数代替
'''
if isinstance(data,pd.DataFrame):
if axis == 0:
q_down = data.quantile(qrange[0])
q_up = data.quantile(qrange[1])
index = data.index
col = data.columns
for n in col:
data[n][data[n] > q_up[n]] = q_up[n]
data[n][data[n] < q_down[n]] = q_down[n]
data = (data - data.mean())/data.std()
data = data.fillna(0)
else:
data = data.stack()
data = data.unstack(0)
q = data.quantile(qrange)
index = data.index
col = data.columns
for n in col:
data[n][data[n] > q[n]] = q[n]
data = (data - data.mean())/data.std()
data = data.stack().unstack(0)
data = data.fillna(0)
elif isinstance(data,pd.Series):
name = data.name
q = data.quantile(qrange)
data[data>q] = q
data = (data - data.mean())/data.std()
return data
|
 【免费申请】7 * 24 小时模拟仿真交易,注154590 人气#QMT投研数据服务
【免费申请】7 * 24 小时模拟仿真交易,注154590 人气#QMT投研数据服务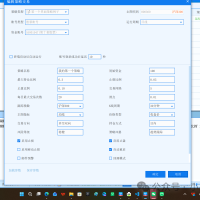 量化研究--QMT开发漂亮的界面策略75 人气#量化经典
量化研究--QMT开发漂亮的界面策略75 人气#量化经典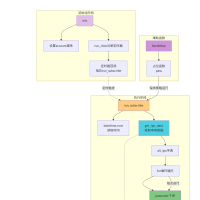 量化研究--QMT实现新股新债申购76 人气#QMT投研数据服务
量化研究--QMT实现新股新债申购76 人气#QMT投研数据服务 刚开始学者写代码,出现这个提示,是个什么98 人气#有问必答
刚开始学者写代码,出现这个提示,是个什么98 人气#有问必答

