切换到宽版
首页
Index
论坛
BBS
商城
知识库
因子看板
迅投学堂
策略代写
用户中心
登录
立即注册
圈子
Group
迅投QMT社区
»
论坛
›
产品服务
›
QMT投研数据服务
›
量化经典
›
1
返回列表
发布新帖
1
2149
0
*******0079
发表于 2025-5-21 15:55:44
|
显示全部楼层
阅读模式
1
回复
收藏
0
举报
返回列表
发布新帖
回复
高级模式
B
Color
Image
Link
Quote
Code
Smilies
您需要登录后才可以回帖
登录
|
立即注册
本版积分规则
发表回复
回帖后跳转到最后一页
*******0079
主题
52
回帖
13
积分
0
图文热点
请教大神,策略交易=》批量预埋单的问题
39 人气
#有问必答
为什么最近xtdata.get_full_tick经常返回空
68 人气
#有问必答
QMT策略 默认品种怎么改成期货?急!!
64 人气
#有问必答
【圈子推荐】《免费·5分钟策略调试》适合
95506 人气
#QMT投研数据服务
推荐话题
1
【免费申请】7 * 24 小时模拟仿真交易,注册即开通!
144887 阅读
davidfnck
2
【有问必答专区规则说明】提问必读!
80992 阅读
心如止水
3
【2025最新】各家券商支持QMT的情况及对应资金门槛
138014 阅读
davidfnck
4
不会代码的进,AI 编写量化策略代码工具经验分享—现已支持QMT [亲测实盘有效]
6232 阅读
*******7202_a21K2
5
不会代码的进,AI编写QMT/miniQMT量化策略代码工具经验分享 [亲测实盘有效]
4557 阅读
*******7202_a21K2
最新发布
下载历史期货数据
请教大神,策略交易=》批量预埋单的问题
股票低开必读:5条黄金口诀,教你反手掌握
从0到500万:普通人翻身的“换挡”逻辑,你
为什么最近xtdata.get_full_tick经常返回空
QMT策略 默认品种怎么改成期货?急!!
qmt教程--qmt常见量化问题解答2
【求助】QMT内置Python策略回测无成交记录
关于我们
关于我们
加入我们
联系我们
服务支持
知识库
策略代写
投研平台
客服专线
400-080-8112
用思考的速度交易,用真诚的态度合作,我们是认真的!
关注公众号
添加微信客服
Copyright © 2001-2026
迅投QMT社区
版权所有
All Rights Reserved.
京ICP备2025122616号-3
关灯
快速发帖
扫一扫添加微信客服
QQ客服
返回顶部
快速回复
返回顶部
返回列表
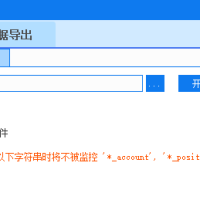 请教大神,策略交易=》批量预埋单的问题39 人气#有问必答
请教大神,策略交易=》批量预埋单的问题39 人气#有问必答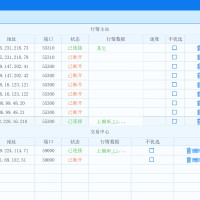 为什么最近xtdata.get_full_tick经常返回空68 人气#有问必答
为什么最近xtdata.get_full_tick经常返回空68 人气#有问必答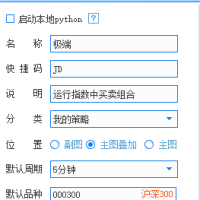 QMT策略 默认品种怎么改成期货?急!!64 人气#有问必答
QMT策略 默认品种怎么改成期货?急!!64 人气#有问必答 【圈子推荐】《免费·5分钟策略调试》适合 95506 人气#QMT投研数据服务
【圈子推荐】《免费·5分钟策略调试》适合 95506 人气#QMT投研数据服务

